System-wide text summarization using Ollama and AppleScript
Local LLMs like Mistral, Llama etc allow us to run ChatGPT like large language models locally inside our computers. Since all the processing happens within our systems, I feel more comfortable feeding it personal data compared to hosted LLMs.
A quick way to get started with Local LLMs is to use an application like Ollama. It’s very easy to install, but interacting with it involves running commands on a terminal or installing other server based GUI in your system.
These are not a huge dealbreakers, but wouldn’t it be nice if you can select a piece of text in any application and ask the LLM to summarize it?
Wouldn’t it be nice if you can select a piece of text in any application and ask the LLM to summarize it?
In order to implement this, we would need to figure out a way to pass the current selected text to the ollama CLI program.
In macOS, there’s a concept call “Services” which allows you to pass data from one app to another. For example. if you select a piece of text in most applications and right click, you would see this “Services” menu.
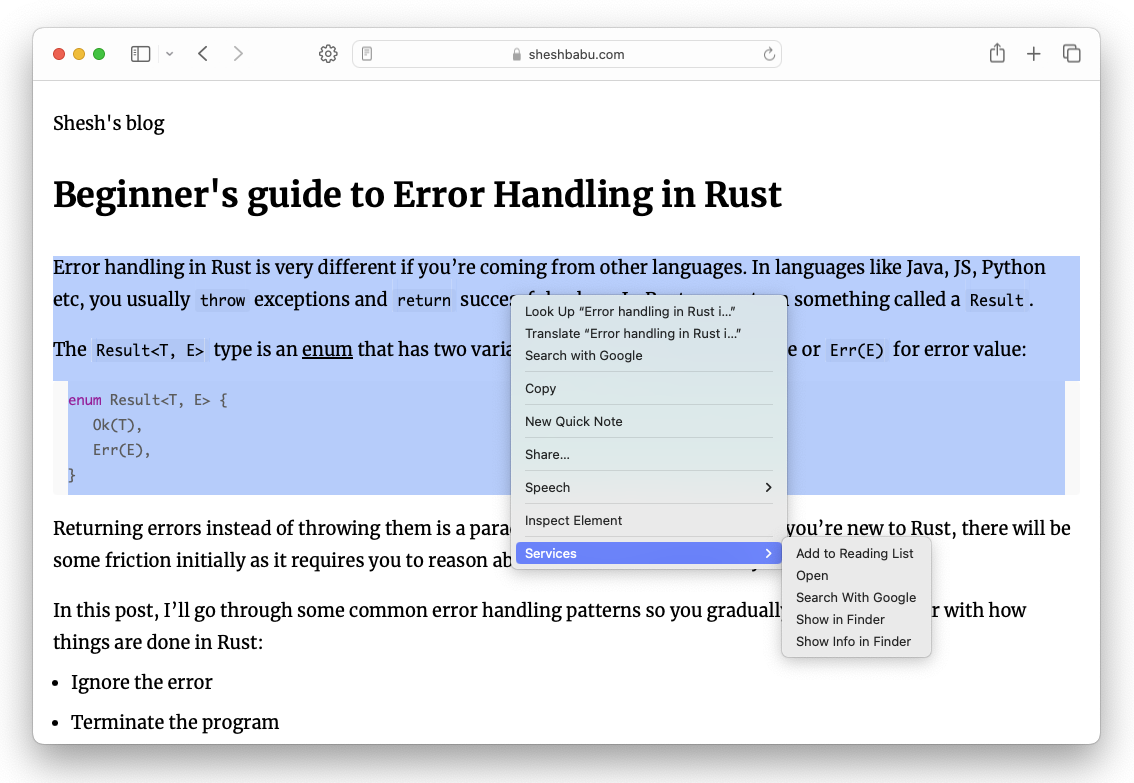
We can use this feature to send data to the ollama CLI program.
To implement this, we need to use a builtin macOS application called “Automator”. Simply launch Automator, select “New Document” in the file picker dialog and choose “Quick Action” as the document type.
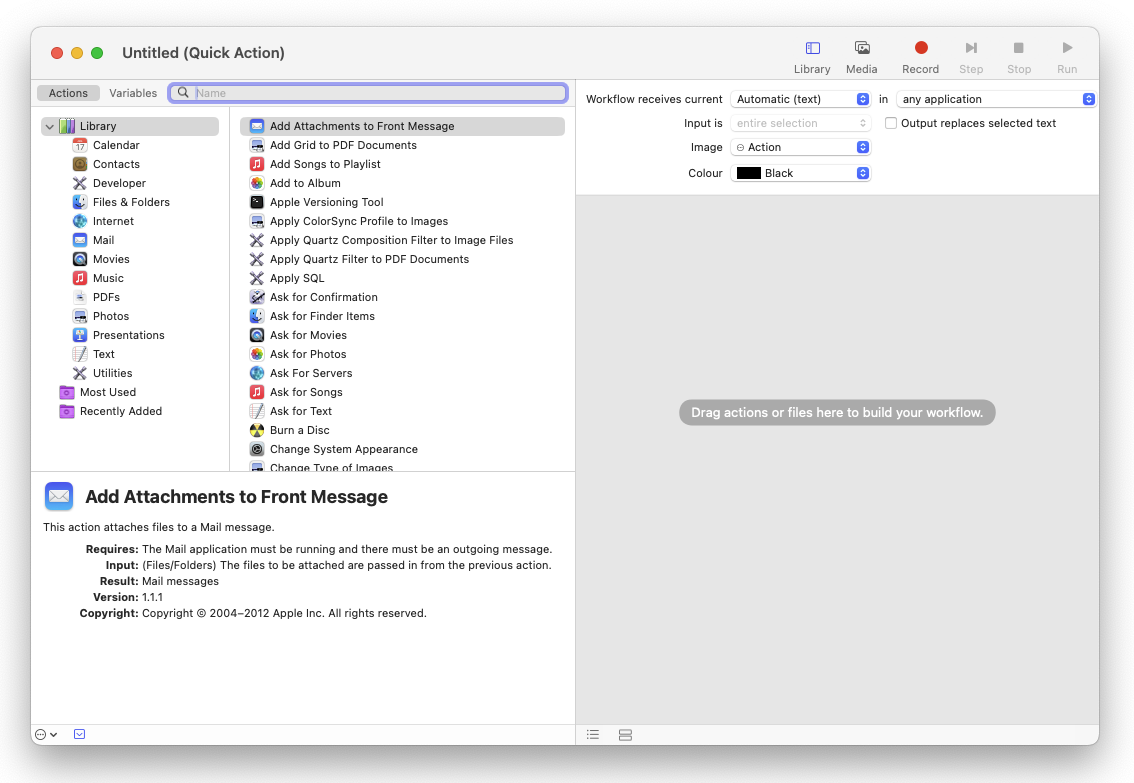
You should see something like the above.
Add “Run Shell Script” and “Run AppleScript” actions as shown in the below screenshot and copy paste the following into them:
/usr/local/bin/ollama run mistral summarize:on run {input, parameters}
display dialog (input as text)
return input
end run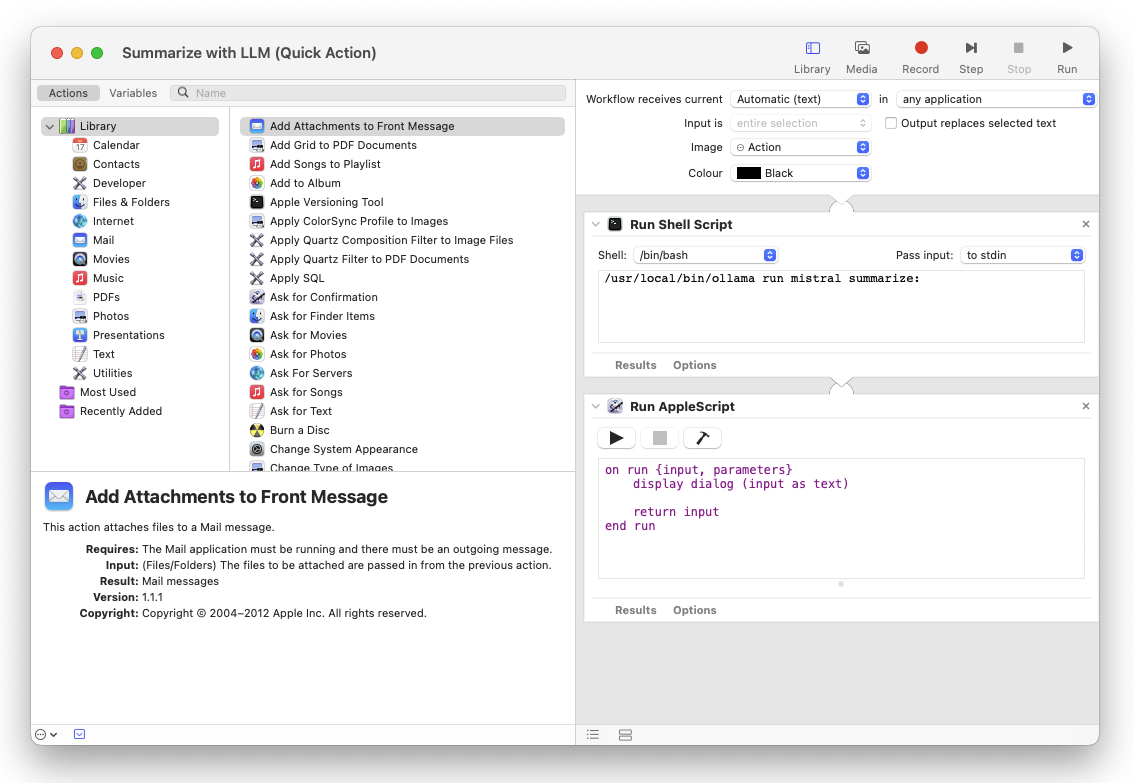
Save this Quick Action as “Summarize with LLM” and you should see it in the Services menu.
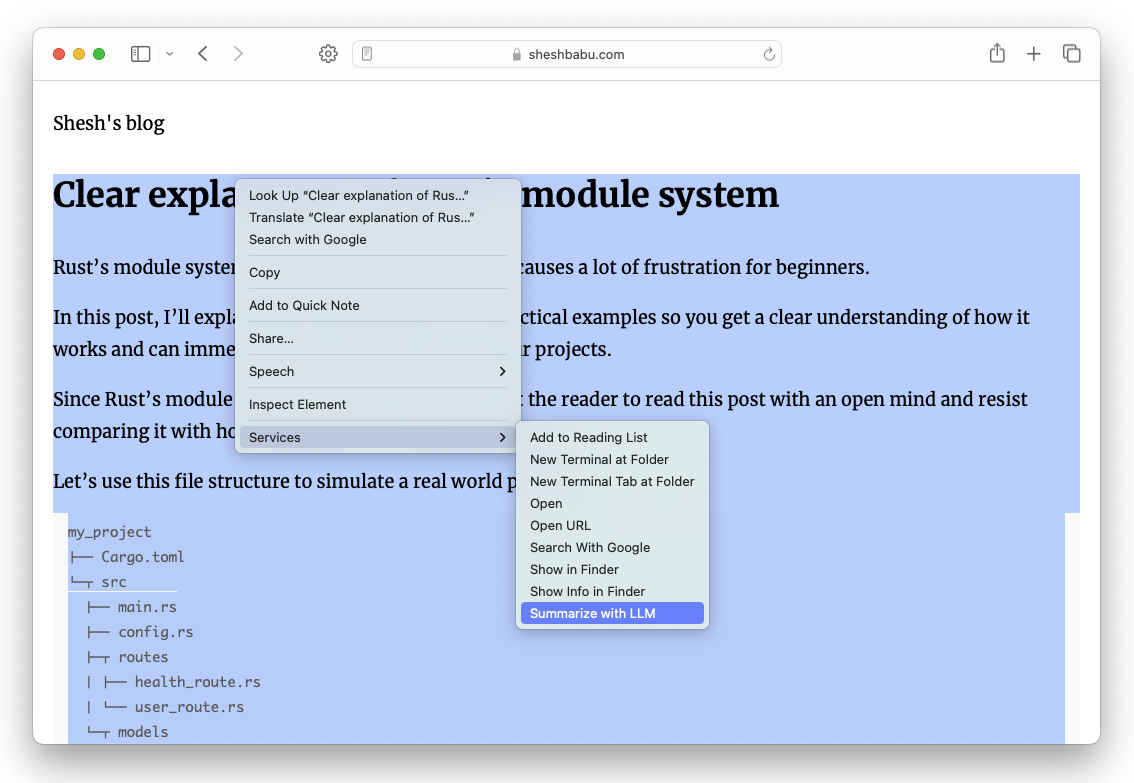
Let’s try this out! I select the content of a blog post and choose “Summarize with LLM”. After a few seconds, I will see a summarized version of the selected content.
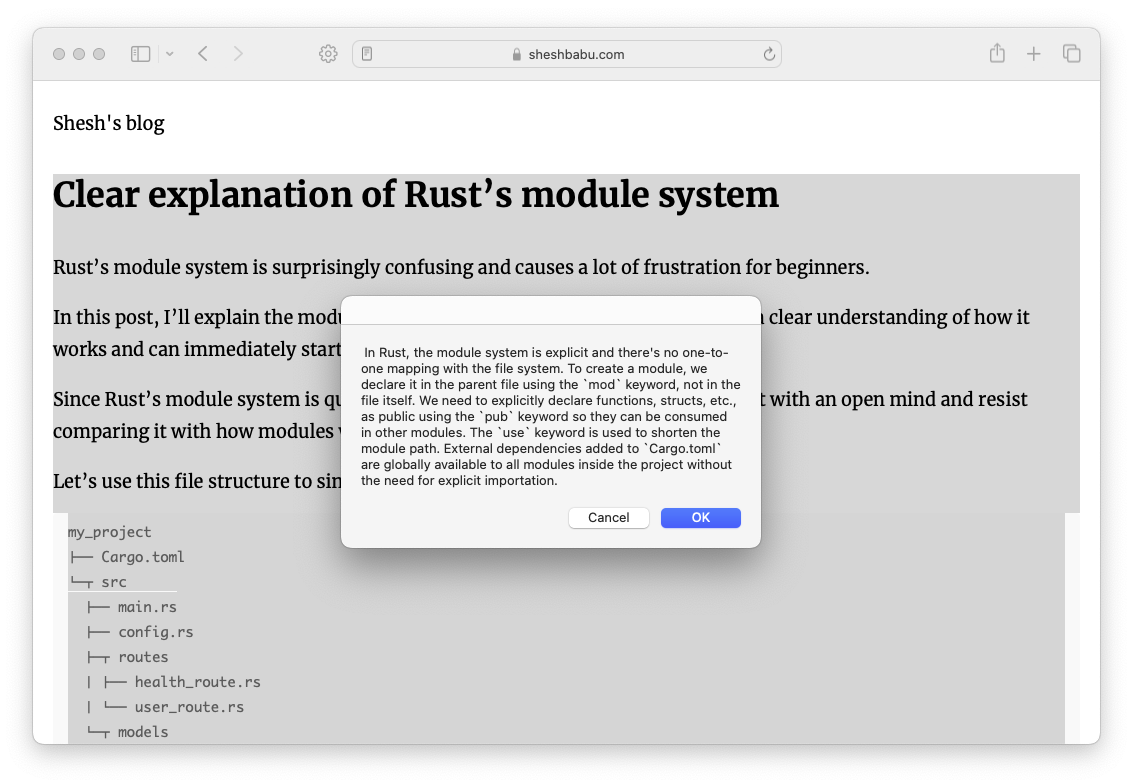
This Quick Action can be used in most applications, try it in your notes, email, etc!
Keep in mind that the first call to this Quick Action would take many minutes as the LLM needs to be downloaded into your machine. Subsequent invocations should only take a few seconds depending on how fast your machine is.