System Design for Entity Resolution
Entity Resolution (also known as Record Linkage, Data Fusion, Deduplication etc) is the process of identifying the same real-world entities (person, company, product etc) from two or more different datasets and combining them into a unique “golden record”. This golden record would serve as an authoritative source of truth for all entities in your organization.
This post aims to serve as a guide for those planning to implement an entity resolution system inside your organization. As mentioned in my previous post, every entity resolution project presents unique challenges based on cleanliness and scale of the data sources, so your design might look different from this and that’s totally fine. Even if you’re thinking of buying an off-the-shelf solution, it’s still useful to know the different aspects of such systems so you can make an informed purchasing decision.
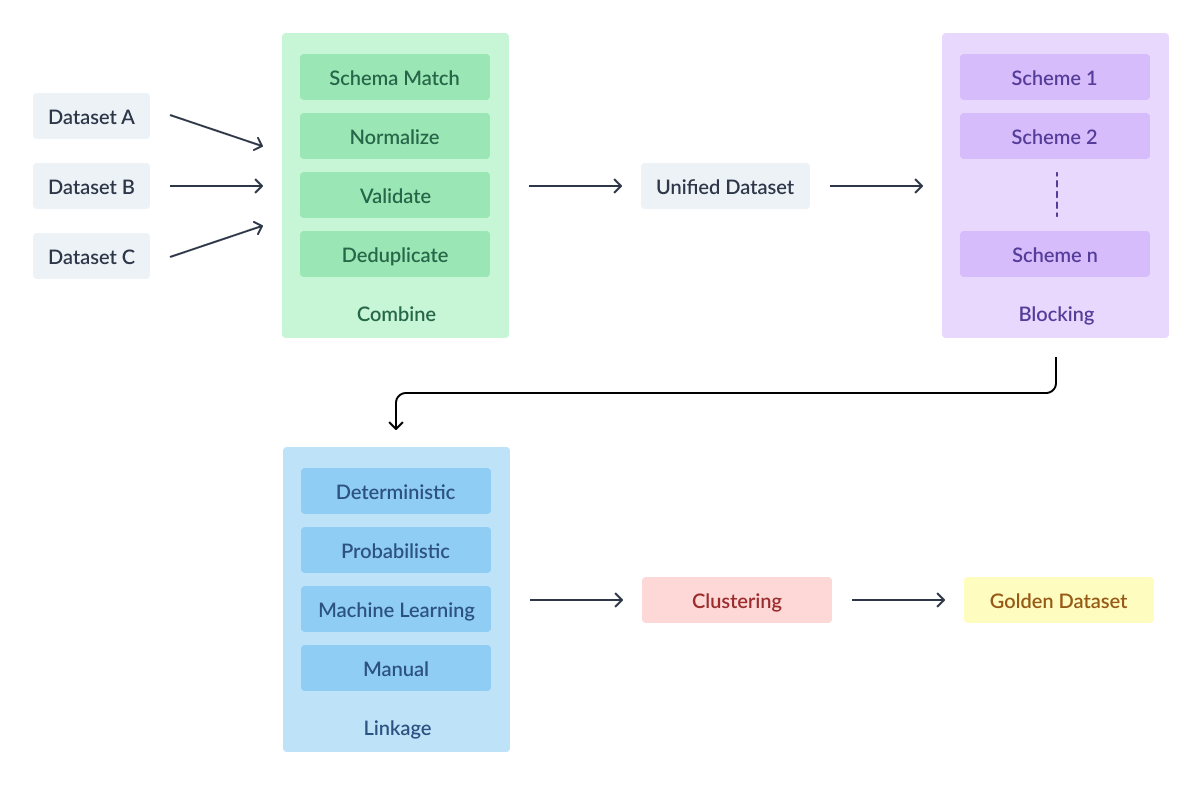
High level stages
Entity Resolution typically has the following stages:
- Combine
- Blocking
- Linkage
- Clustering
Combine
The first step is to ingest and consolidate the data from different places like S3, Excel, SQL database etc into a single unified dataset.
Schema Matching
In this step, we need to select which attributes across the different datasets have the same information. These selected attributes would help in the downstream linkage process and would finally end up as attributes of the final golden record.
Validation
Depending on your data sources, you might need to implement certain validation rules to make sure that clean data is passed on to downstream stages. These might be about ensuring the email addresses are valid, phone numbers have the correct length etc. If the attributes are incorrect, depending on your use case, you can decide to either convert them to NULL or skip ingesting the record altogether.
Normalization
There’s a good chance different data sources have the same attribute captured in different formats. For example, one data source might collect date of birth as “01 Jan 1900” and other might collect that as “1900/01/01”. So in this step, you’ll need to normalize/standardize these into the same formats so they’re more useful in downstream stages. It’s helpful to maintain both “raw” and “clean” versions of the attributes for future troubleshooting.
Deduplication
Some data sources have duplicate records for the same entity. It’s better to clean these up earlier in the process before you merge this data source with other data sources. “Deduplication” is a special case of record linkage where the linkages happen within a single dataset as opposed to happening across multiple datasets.
Blocking
One of the challenges of entity resolution is that the data is huge. We need to do a pairwise comparison between the records of the two datasets and decide whether they match or not. This pairwise comparison scales quadratically - if you have m number of records in one dataset and n number of records in the other, then the number of comparisons is m * n. If you remove duplicates, it becomes (m * n) / 2.
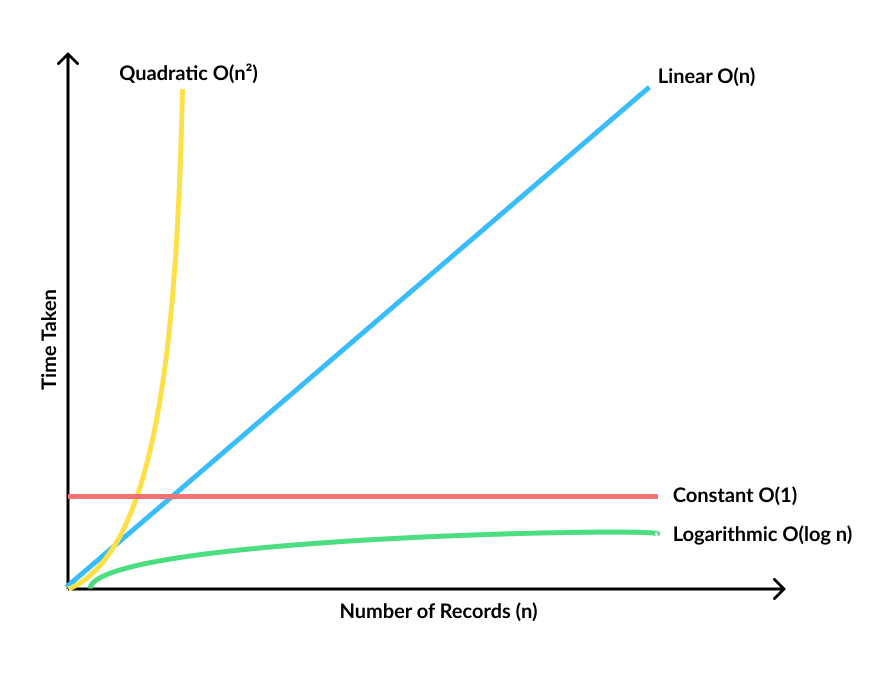
In order to do this efficiently, we need to reduce the search space. If you think about this, it doesn’t make sense to compare every single record. We need to figure out a way to group the records that are likely to be a match. This step is called “blocking” or “indexing”.
Linkage
In this stage, we make a decision to link a record from one data source to its identical record in another data source. It’s useful to store these links as a graph as linkages are usually transitive in nature.
Deterministic Linkage
This is a rules-based approach. If two records have one or more attributes with identical values, then they’re classified as a match and linked together.
- Direct Deterministic Linkage: The attributes used are unique identifiers like SSN, email etc.
- Exact/Strict Deterministic Linkage: The attributes must be exactly the same in the record pair.
- Approximate Deterministic Linkage: The attributes can have minor differences between two records.
- Stepwise Deterministic Linkage: The attributes are matched in a series of less restrictive steps.
Deterministic linkage is the oldest, simplest and computationally fastest approach. It avoids false matches and provides acceptable results. The downside is that it misses out a lot of matches because of recording errors, missing values, variations, changes over time, etc.
Probabilistic Linkage
If unique identifiers are unavailable, then we need to use an evidence-based approach. The likelihood of two records referring to the same entity increases if they share the same attribute values. The probability increases as more attributes match, decreases if there’s a mismatch.
ML-based Linkage
If we’re able to provide labelled data for which record pairs match or don’t match, then a ML model can be trained to do the classification.
Clustering
Once we’re done with the linkage process, we can see clusters forming in the graph. Each of these cluster is a unique entity across multiple data sources. A golden record is created from each cluster by giving it an unique identifier and merging the attributes from records originating from different sources. If there’s a conflict in attribute value, we can use a data source prioritization list to decide which data source to pick that value from. It’s helpful to keep the mapping between this golden record id and the ids of records from different data sources.
Conclusion
Whether you’re building this in-house or buying an off-the-shelf solution, it’s important to have a decent understanding of the data sources you’re working with. It’s better to do an EDA on each data source to understand the format of the attribute values, whether the values are valid, are there any duplicate entities within that data source etc. It’s also advisable to consult with a domain expert before starting the implementation. Entity resolution involves a lot of defensive programming, so the more you know about the data sources, the more surprises you can avoid in future.
References
- Linking Data for Health Services Research
- CIDACS-RL: a novel indexing search and scoring-based record linkage system for huge datasets with high accuracy and scalability
- Automatic Linkage of Vital Records
- A Theory for Record Linkage
- An Interactive Introduction to the Fellegi-Sunter Model for Data Linkage/Deduplication
- A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication
- A Survey of Blocking and Filtering Techniques for Entity Resolution