Graph Retrieval using Postgres Recursive CTEs
Did you know you can use Postgres as a graph database for certain usecases?
Let’s say you have a graph like this:
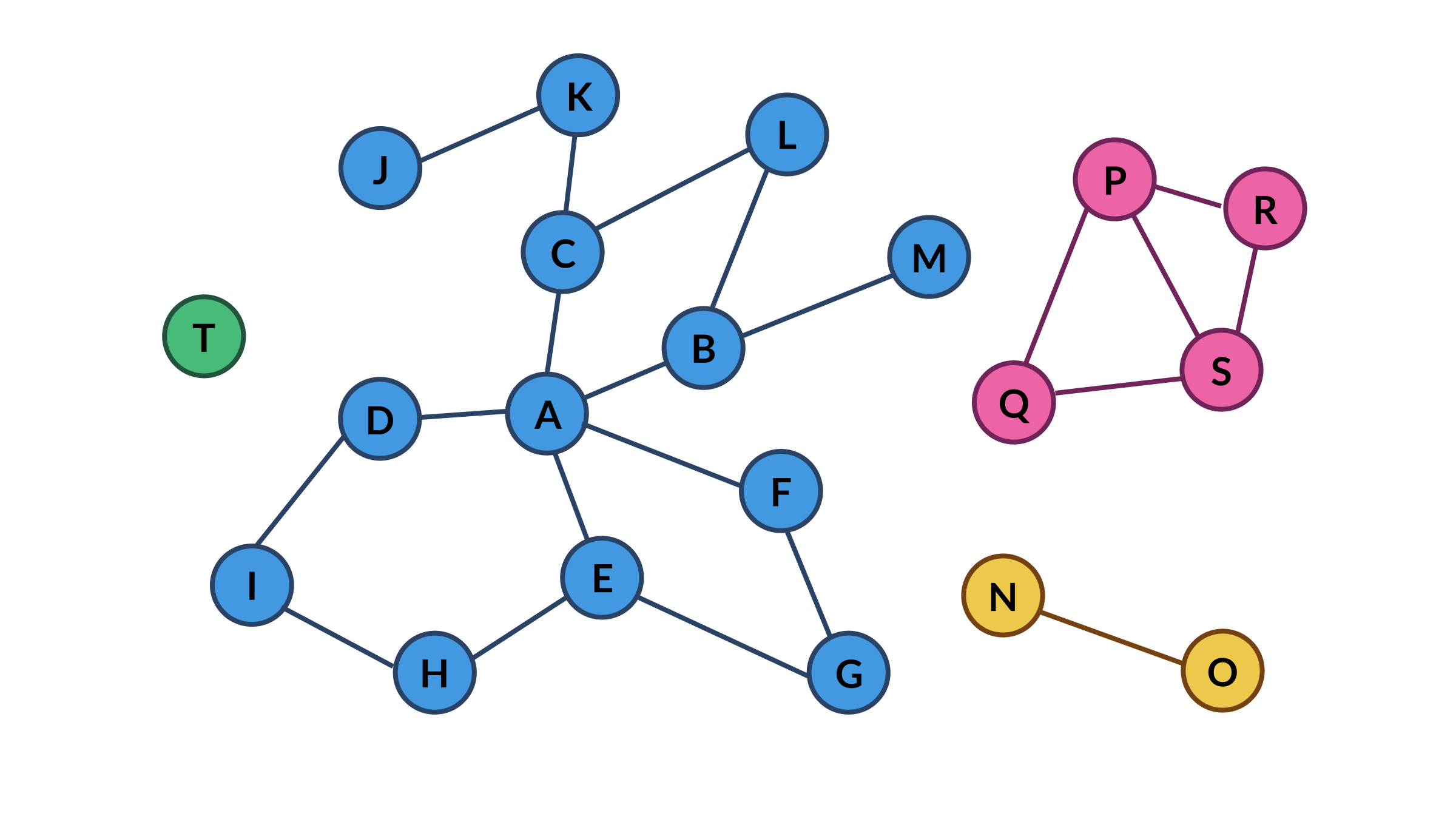
We can build this graph in NetworkX:
import networkx as nx
G = nx.Graph()
G.add_edges_from([
("A", "B"),
("A", "C"),
("A", "D"),
("A", "E"),
("A", "F"),
("E", "G"),
("F", "G"),
("E", "H"),
("H", "I"),
("D", "I"),
("J", "K"),
("C", "K"),
("C", "L"),
("B", "L"),
("B", "M"),
("N", "O"),
("P", "R"),
("P", "Q"),
("P", "S"),
("R", "S"),
("Q", "S")
])To store this in Postgres, create an edges table:
CREATE TABLE IF NOT EXISTS edges (
u TEXT,
v TEXT
-- add other edge attributes
)Insert the edges into the table:
INSERT INTO edges (u, v)
VALUES
('A', 'B'),
('A', 'C'),
('A', 'D'),
('A', 'E'),
('A', 'F'),
('B', 'L'),
('B', 'M'),
('C', 'K'),
('C', 'L'),
('D', 'I'),
('E', 'G'),
('E', 'H'),
('F', 'G'),
('H', 'I'),
('J', 'K'),
('N', 'O'),
('P', 'R'),
('P', 'Q'),
('P', 'S'),
('Q', 'S'),
('R', 'S');Now that we have the graph stored, let’s see how to retrieve a connected component from Postgres. If we want to retrieve all the nodes that are connected to “A”, we can use this recursive CTE:
WITH RECURSIVE cc AS (
SELECT
u, v
FROM
edges
WHERE
u = 'A' OR v = 'A'
UNION
SELECT
e.u, e.v
FROM
edges e
INNER JOIN
cc c ON
c.u = e.v OR
c.v = e.u OR
c.v = e.v OR
c.u = e.u
)
SELECT * FROM cc;Here’s how it works visually:
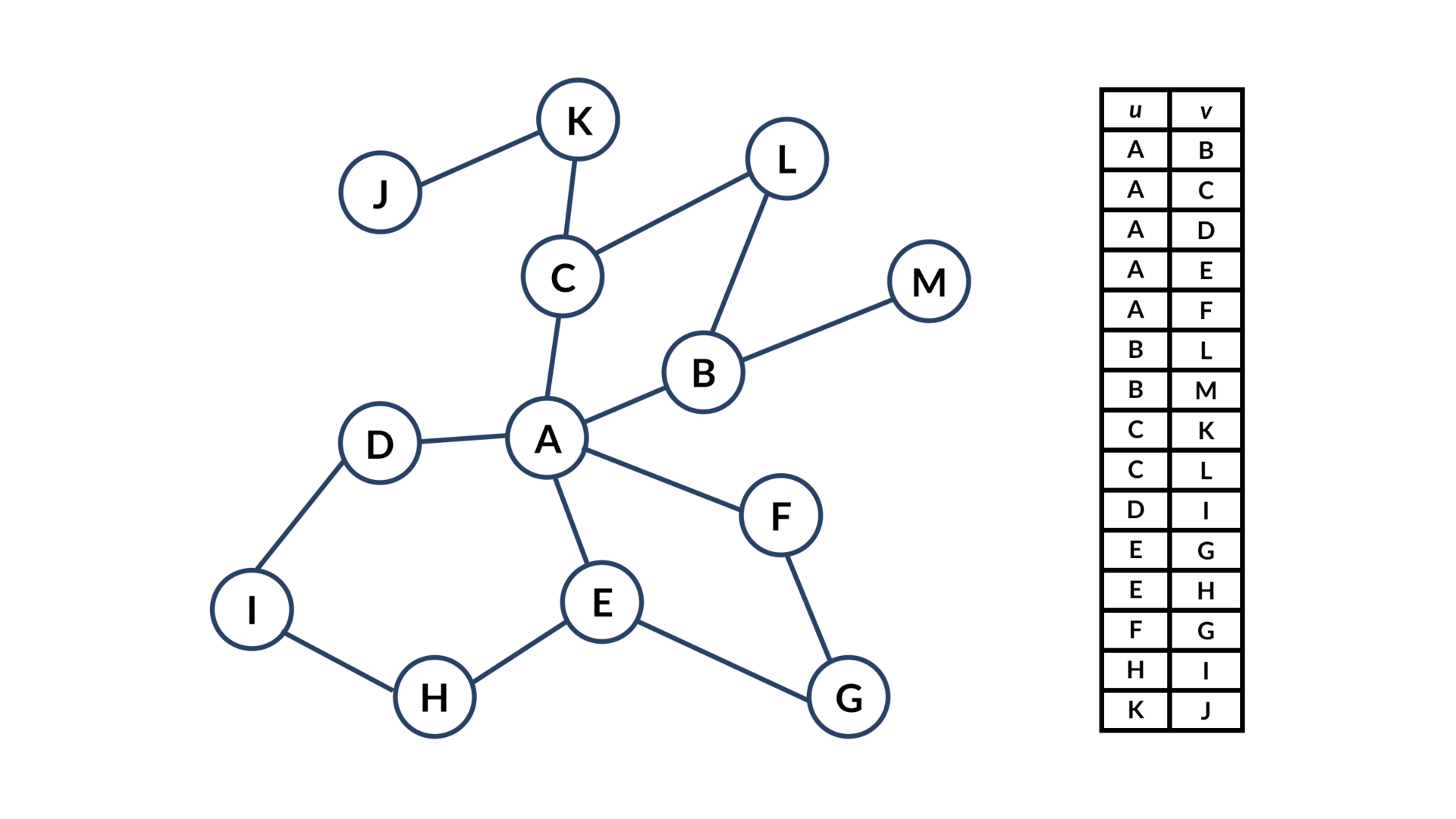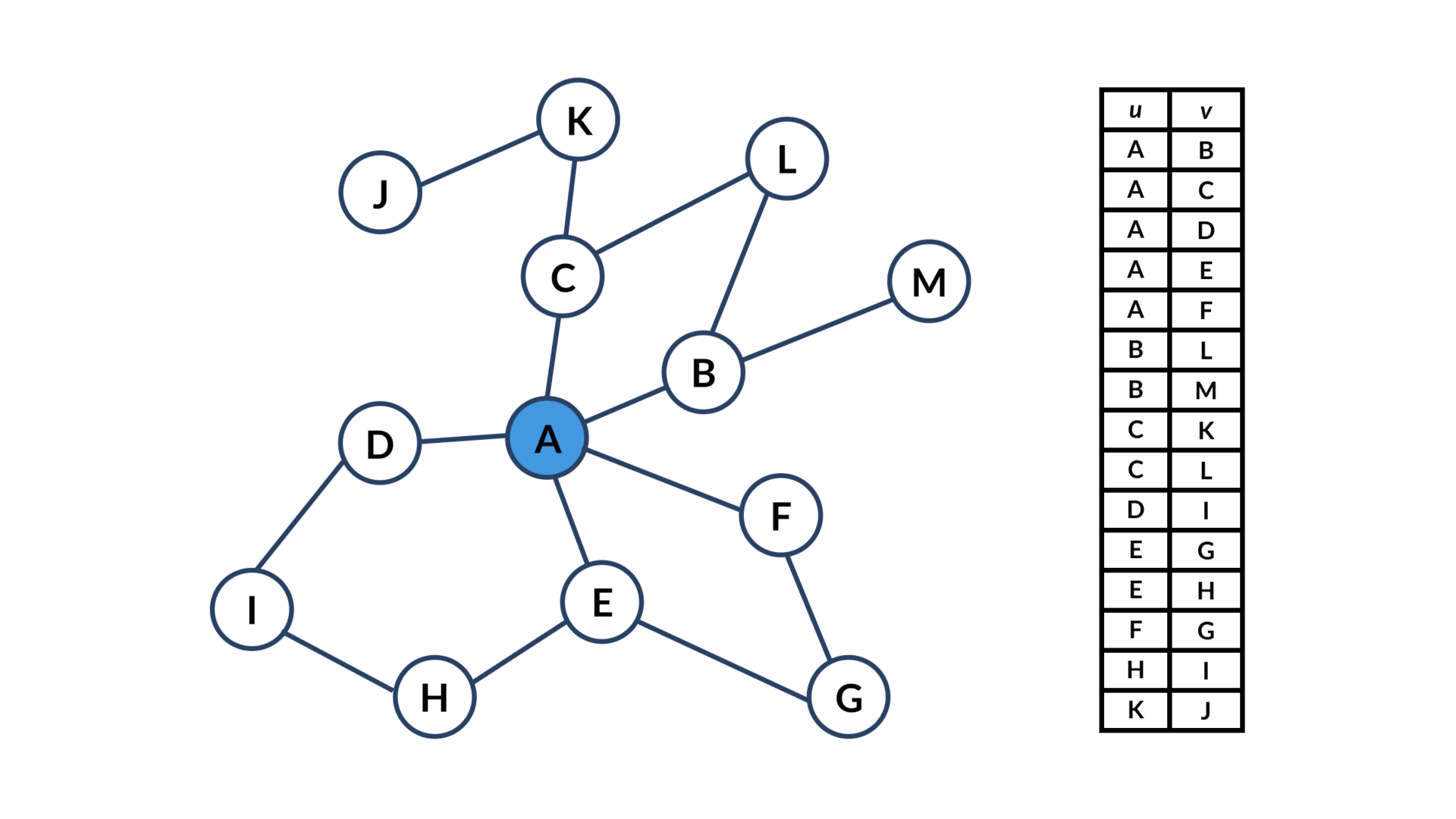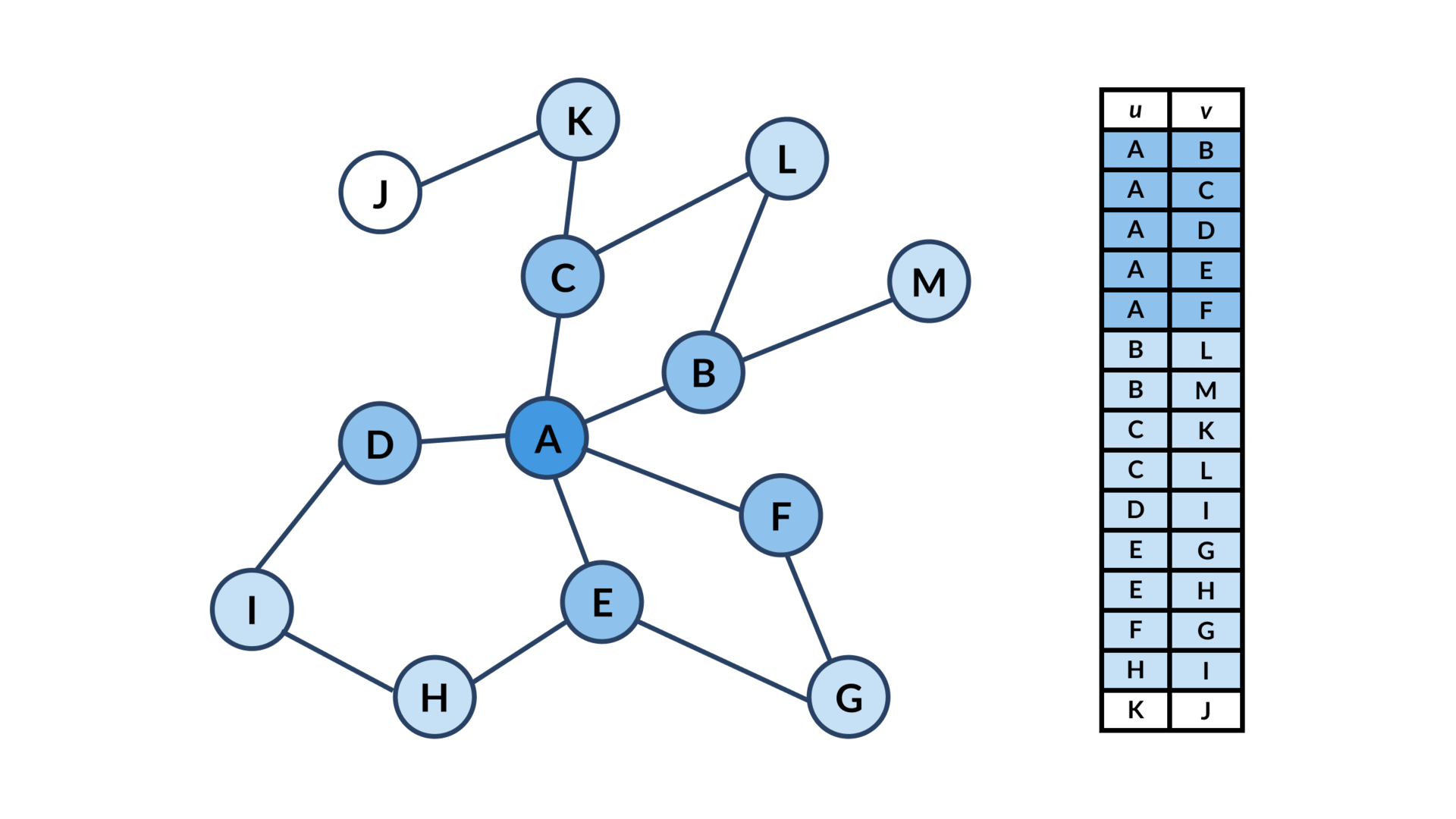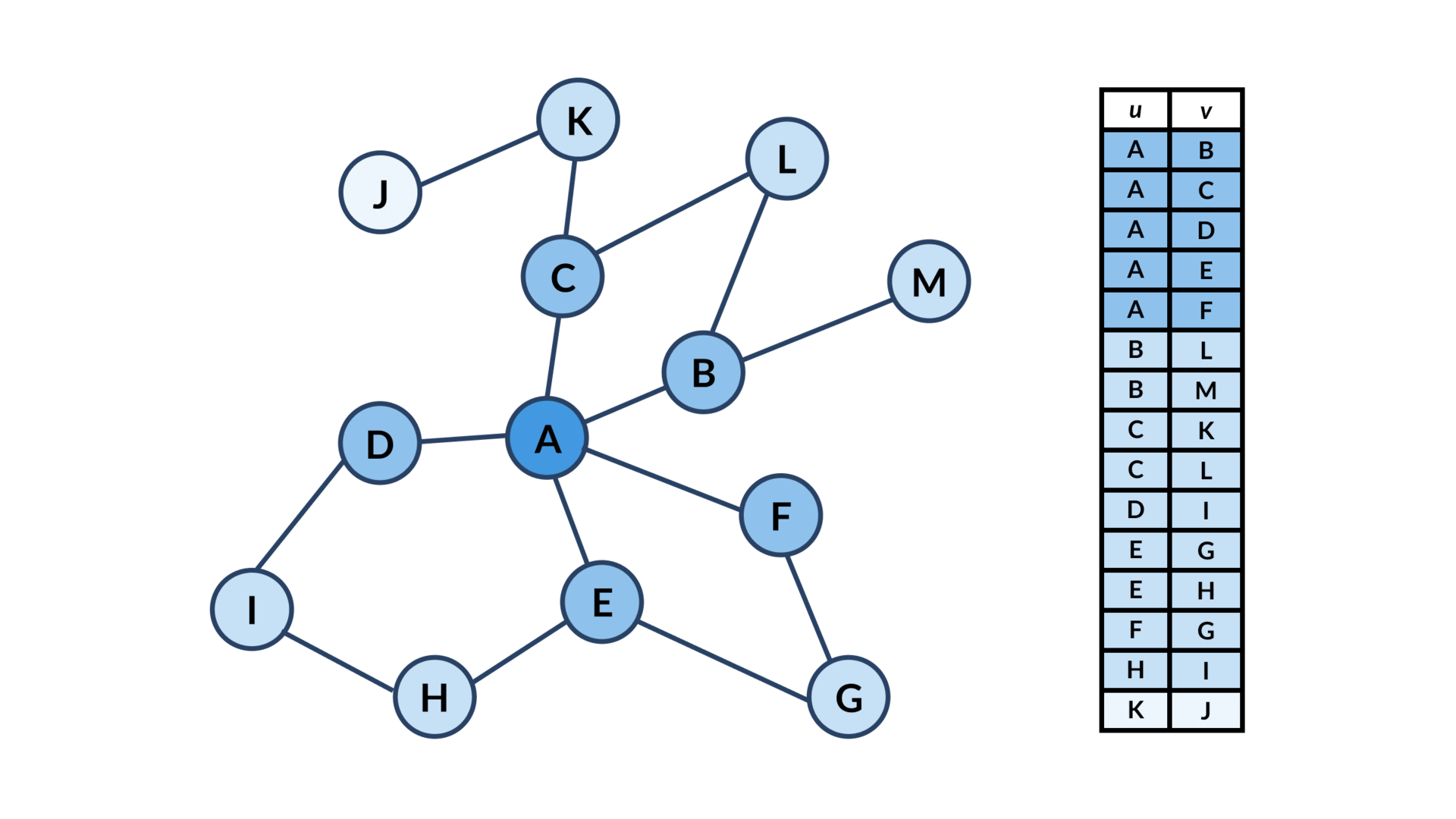
Conclusion
I’m honestly surprised how well this works. I’ve tried this with graphs with millions of edges, and it works great!
The beauty of using Postgres to store graphs is that if your entities (nodes) are already stored inside other tables, then you’re able to keep both the entity metadata and relationships (graph) in the same database, thereby avoiding data synchronization between Postgres and a graph database.
Couple of caveats:
- The graphs I used are disjoint undirected graphs with millions of connected components. These are very common for entity resolution use cases.
- After retrieval, I use application-level libraries like NetworkX, igraph, etc to apply graph algorithms. This setup provides me with more graph algorithm options compared to the few available in graph databases like Neo4j etc.
- If your graph is large or can have a high diameter, it’s better to add statement timeouts or limit the recursion depth so the above query doesn’t take a long time. Here’s an example of how to implement them.
- I’ve omitted things like constraints and indexes, these can be added based on your use case.